在 2020 年 9 月 30 日这天,Let’s Encrypt 颁发了六个新证书:一个根证书,四个中间证书和一个交叉证书。这些证书属于改善网络隐私的更大计划的一部分,让 ECDSA 终端证书被更广泛的采纳,和更小的证书体积。
鉴于我们每天要颁发 150 万张证书,这些证书有什么特别?为什么颁发它们?怎么颁发它们?让我们通过解释 CA 是如何思考和工作的来回答这些问题。
背景
每一个被公众信任的 CA (例如 Let’s Encrypt) 都至少有一个根证书被众多的浏览器和操作系统 (例如 Mozilla 和 Google) 的信任跟存储所包含。通过这种方式,用户可以确认他们从网站收到的证书是一个被浏览器信任的机构所颁发的。但是根证书由于它们的广泛传播以及较长的信赖周期,它的秘钥必须被妥善的保护并离线保管,以防止被用来不停地签发。因此 CA 会有若干个中间证书来替代根证书以确保证日常安全。
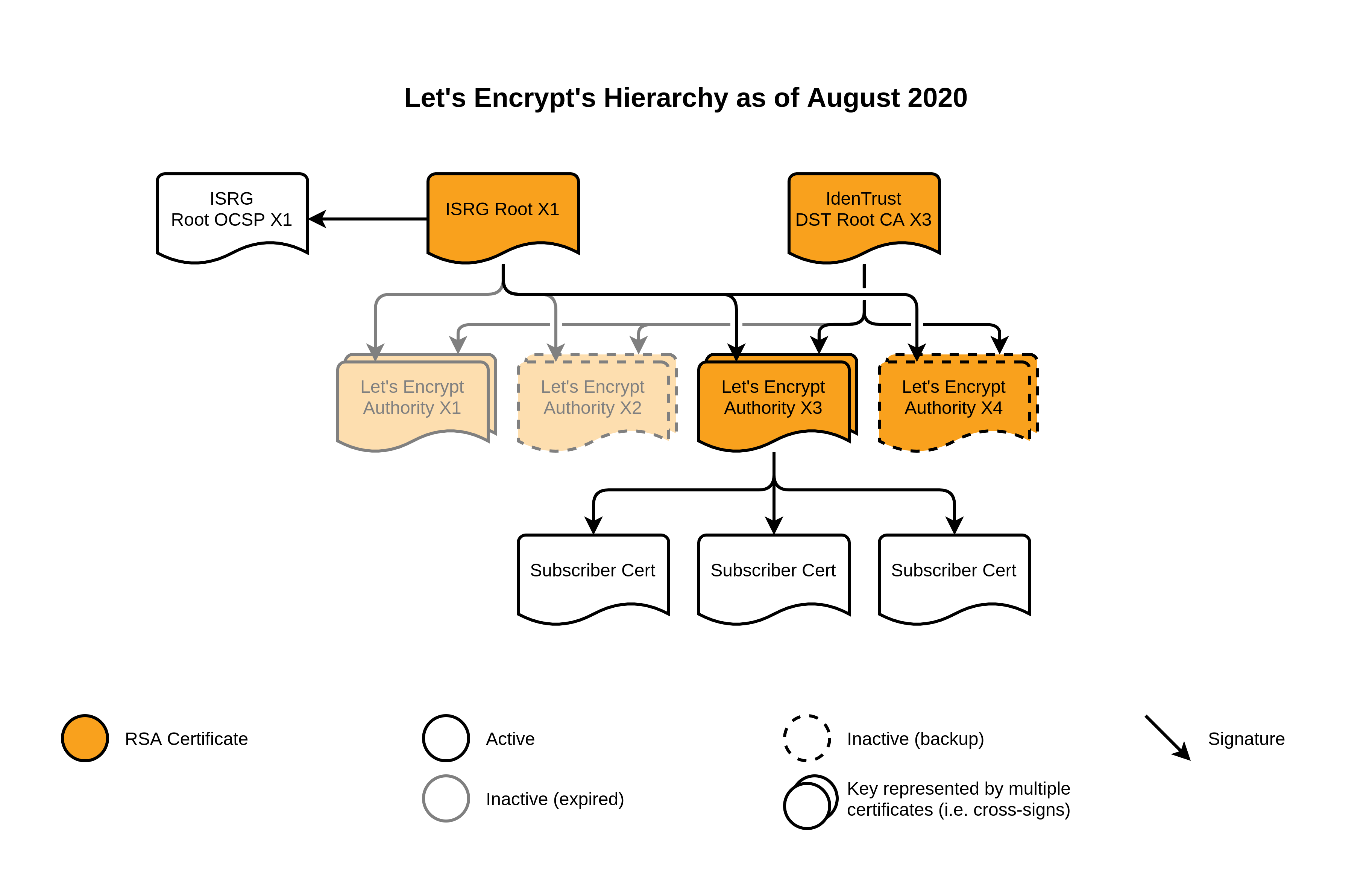
最近 5 年里, Let’s Encrypt 只有一个根证书: ISRG Rott X1,它拥有一个 4096 位的 RSA 秘钥并且有效期直到 2035 年。
也是在这段时间里,我们有了四个中间证书,分别是 Let’s Encrypt Authorities X1, X2, X3 和 X4。 前两个是 Let’s Encrypt 刚开始运营的 2015 年颁发的,有效期为 5 年;后两个是一年后,也就是 2016 年颁发的,有效期 5 年,并将在明年的这个时候过期。所有的这些中间证书都使用 2048 位的秘钥。此外,这些中间证书都由 IdenTrust 公司的 DST Root CA X3 根证书交叉签署,这个证书由另一家广泛被信任的 CA 所管理。
Let’s Encrypt 到 2020 年 8 月的结构图
新证书
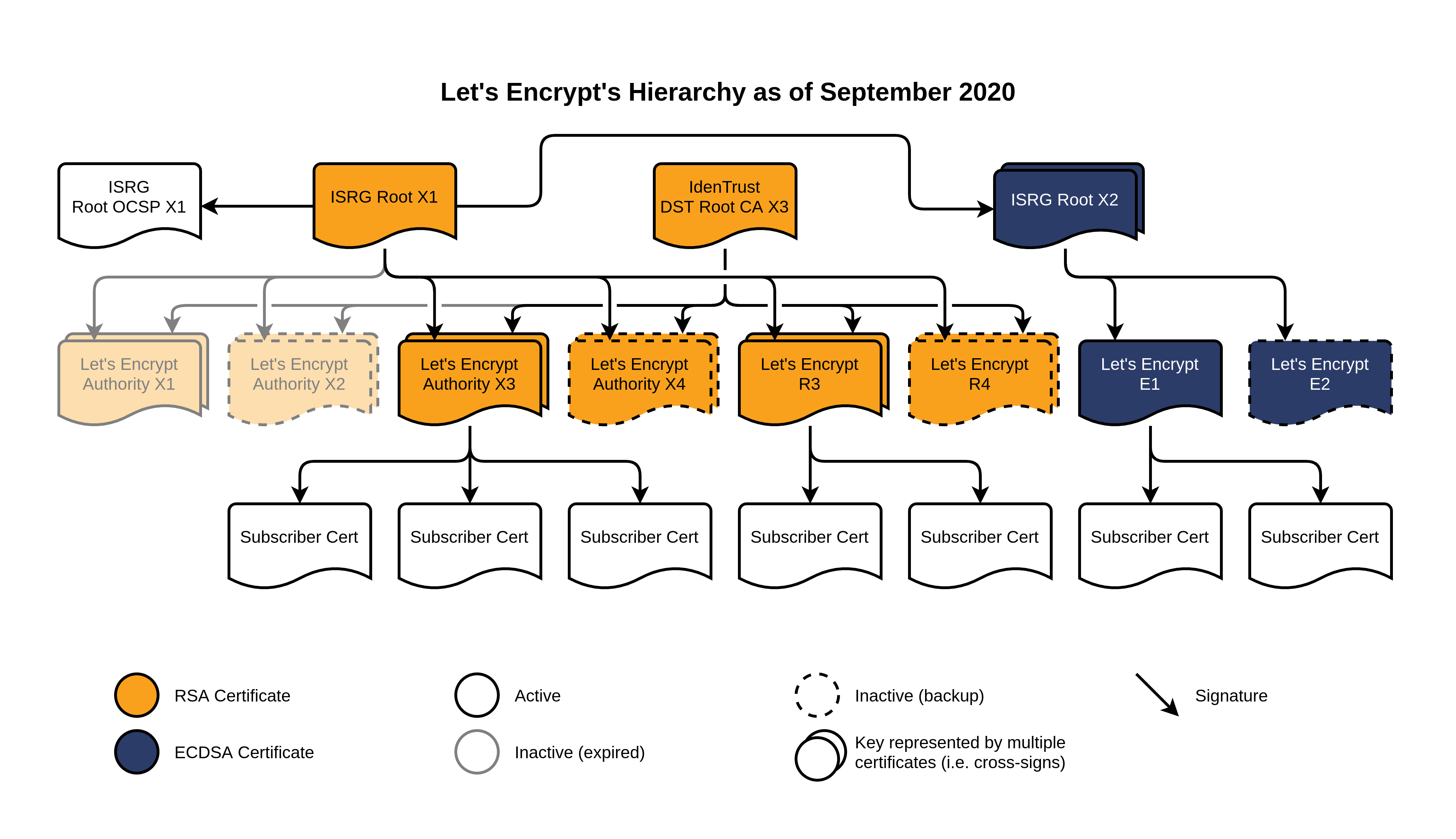
首先,我们颁发了两个 2048 位秘钥的 RSA 中间证书:R3 和 R4. 这两个证书都由 ISRG Root X1 签署,拥有 5 年的有效期。同样交由 IdentTrust 交叉签署。它们实际上是 X3 和 X4 的直接替代,考虑到它们一年后即将到期。我们预计会在今年底把主要的证书颁发流水线切换到使用 R3 证书,不会对证书的颁发和续签的造成实际的影响。
另一个新证书更有意思一点。首先,我们有了一个新的 ISRG Root X2,将会使用 ECDSA P-384 替代 RSA,有效期到 2040 年。由它颁发了两个新的中间证书:E1 和 E2,签名算法也是 ECDSA 并且有效期为 5 年。
值得注意的是,这些新中间证书并没交由 IdentTrust 的 DST Root CA X3 交叉签署, ISRG Root X2 本身由 ISRG Root X1 交叉签署。敏锐的观察者可能也会注意到我们没有通过 ISRG Root X2 颁发有 OCSP 签名的证书。
Let’s Encrypt 到 2020 年 9 月的结构图
既然已经讨论到了技术细节,不妨再深入了解下这个结构的由来。
为什么颁发 ECDSA 的根证书和中间证书
已经有好多文章讨论过 ECDSA 的好处 (相同加密程度下更小的秘钥,更快的加密,解密,签名,验证等操作)。不过对我们来说,更大的好处来自于证书体积的缩小。
每一个通过 https:// 到远程主机的链接都需要一次 TLS 握手。每一个 TLS 握手都需要服务器提供它的证书。校验证书的过程还包括检查证书链(包括直到可信根证书的所有中间证书),这通常也是由有服务器提供的。这就意味这每个链接,一个覆盖各种广告和跟踪像素的页面会包含几十甚至上百个链接,这会需要传输大量的证书数据。并且每个证书都包含自己的公钥和签发者的签名。
一个 2048 位的 RSA 公钥大概 256 字节,而一个 ECDSA P-284 的公钥只有 48 字节。类似的, RSA 的签名会需要额外的 256 字节,而 ECDSA 只需要 96 字节。再考虑到其他一些开销,每个证书能节约大约 400 字节。用这个数乘以你的证书链长度以及每天的链接数,带宽的节省就很可观了。
这些省下的流量不仅会使我们的证书使用者每月节省大量的带宽费用,也惠及那些有限的、受限的终端用户。提高整个互联网的隐私性不仅是采用证书技术,也包括这让这些技术更经济。
此外由于我们很关心证书的大小,我们还采取了一些其它手段来让证书变得更小。我们把证书的主体名字由 “Let’s Encrypt Authority X3” 缩减到 “R3”,这是给予机构名称里已经提供了冗余的 “Let’s Encrypt”。同时我们还缩短了 Authority Information Access Issuer 和 CRL Distribution Point 的 URL 长度,我们还整个砍掉了 CPS 和 OCSP 的 URL。通过这些手段我们能够在不丢失实质性信息的情况下让证书再缩小 120 字节。
为什么交叉签署 ECDSA 根证书
交叉签署是新根证书从被签发到被主流信任的过渡阶段很重要的步骤。我们知道 ISRG Root X2 可能需要 5 年甚至更长时间才能被广泛接受,所以 E1 中间证书签发的证书如果希望被信任,一定需要证书链中某处的交叉签署。
我们基本上有两种方法:用现有的 ISRG Root X1 交叉签署 ISRG Root X2,或者用 ISRG Root X1 直接交叉签署 E1 和 E2。接下来我们就来分析下这两种做法分别有什么优缺点。
交叉签署 ISRG Root X2 意味着如果一个用户在信任库里有 ISRG Root X2,那么该证书链就是 100% ECDSA ,可以利用前文所述的快速校验。并且在接下来的几年里随着 ISRG Root X2 被加到越来越多的信任库里,ECDSA 终端证书的验证会越来越快而不需要用户或者网站做什么。这么做的代价是,只要 X2 还不在信任库里,用户的客户端就需要验证两个中间证书包括 E1 和 X2 直到 X1 根证书。这显然增加了证书验证的时间。
直接交叉新签署中间证书也有问题。一方面所有证书链的长度是相同的,在证书使用者和被广泛信任的 ISRG Root X1 之间只有一个中间证书。但是另一方面,随着 ISRG Root X2 获得越来越广泛的的信任,我们需要通过切换到另外一个链来
保证所有都能享受全链 ECDSA 的好处。
最终我们认为全链 ECDSA 更重要,所以我们选择了第一个方案,交叉签署 ISRG Root X2 证书。
为什么我们不提供 OCSP Responder 了
OCSP 协议是用户客户端用来发现并实时检查证书是否被吊销的一种方式。无论何时,一个浏览器如果想要知道证书是否有效,它可以通过访问证书里的一个 URL 就能得到是或否的答案,这个结果是由另一个可以被用相同方式检查的证书签名。这对终端用户的证书来说是非常棒的,应为请求响应体积很小并且速度很快。根据访问的站点不同,任何一个用户可能会关心(因此必须下载)海量证书集合的有效性。
但是中间证书只是海量证书的一个小小的子集,并且通常是广为人知的,也很少被吊销。因此,提供一个所有常用中间证书的吊销列表可能会更有效。我们的中间证书都包括一个 URL,通过这个 URL 浏览器可以下载证书的 CRl。实际上有些浏览器甚至会在例行更新里带上 CRL 列表集合,这使得在检查中间证书有效性的时候不需要再进行一次额外的访问开销,从而为大家创造更好的体验。
实际上用来指导 CA 的 Baseline Requirements 最近一次更新表明,中间证书已经不再强制要求包含一个 OCSP URL,而是可以只通过 CRL 来发布自己的吊销信息。鉴于此,我们从中间证书里移除了 OCSP URL,即我们不再需要为所有 ISRG Root X2 颁发的中间证书提供 OCSP Responder。
总结
至此我们已经介绍了新证书,最后再提一点:我们是怎么颁发这些证书的。
创建新根证书和中间证书是一个大事件,因为它们是被监管的的并且需要极其小心地看管好秘钥。这个事件是如此重要以至于颁发新证书被称作是“仪式”。在 Let’s Encrypt 我们非常推崇机器自动化,所以我们想要这个仪式的人为干预越少越好。
在过去的几个月里我们为这个仪式建立了一个工具,如果输入正确的配置,就能够生成所需的秘钥、证书和交叉签名请求等。我们还建立了一个仪式的 Demo 来说明这个配置文件可以并且允许所有人来运行和检查结果。我们的 SRE 搭建了一个相同并配有硬件安全模块的网络,自己执行了若干次仪式以确保整个流程完美无暇。我们与技术委员会、社区和若干邮件列表分享了这个 Demo,在这个过程中获得了很多有价值的反馈,其中一些甚至影响了上面我们提到的一些决定。最终、在 2020 年 9 月 3 号,我们的执行董事和 SRE 在一个安全的数据中心碰面并执行了整个仪式,并且有录像以供审计用。
现在仪式已经完成。我们已经更新了证书页面上关于新证书的细节,并且开始着手于申请将我们的新根证书加入到若干个信任库中。我们会在未来几周里开始用新中间证书来签发证书,并在社区论坛里发布进一步的公告。
希望我们关于新证书结构的导览是有趣的和干货的。我们期待继续通过一张张的证书来改进互联网隐私。我们由衷感谢 IdenTrust 在早期和后来不间断的支持我们让互联网更安全的愿景。
我们依靠社区和支持者来提供我们的服务。如果你的公司或者机构希望可以赞助 Let’s Encrypt 可以发邮件到 sponsor#letsencrypt.org 。我们需要您力所能及的帮助、
